芯瞳成功研发GPU,实现与DeepSeek模型完美兼容!
领跑AI时代,芯瞳GPU引领革命潮流!
2月10日获悉,国内GPU厂商芯瞳半导体昨日表示,其自主研发的GPU已经顺利完成与DeepSeek模型的兼容适配工作。
芯瞳表示:
芯瞳CQ2040系列GPU在采用llama.cpp推理框架的基础上,已经在我国自主构建的AI全链路技术闭环环境中,成功完成了对DeepSeekR1模型的兼容与适配工作。这一成果不仅展示了国产GPU在人工智能领域的技术实力,也为我国在关键核心技术上实现自主可控提供了有力支撑。这标志着我国在高性能计算和人工智能领域取得了新的突破,未来有望进一步推动相关产业的发展与创新。 通过这样的实践,我们可以看到国产GPU在实际应用中的潜力和价值,同时也体现了我国在构建自主可控技术体系方面所取得的重要进展。这对于提高我国在全球科技竞争中的地位具有重要意义。
这表明芯瞳在国产GPU与国际领先的AI模型兼容性方面取得了重要进展。
芯瞳还一道推出了三种全国产软硬一体化 AI 解决方案,分别可满足不同规模的客户需求:
单机单卡版:配备1颗芯瞳GPU,支持部署DeepSeekR132B参数模型,适合个人用户及小规模团队使用。
多卡版:搭载4到8颗芯瞳GPU,DeepSeekR170B能够部署复杂的参数模型,适合中小企业使用。这款设备不仅支持多人同时访问,还大大提升了处理效率。对于资金和技术资源有限的中小企业而言,这无疑是一个好消息,因为它能够在不增加过多成本的情况下提升业务处理能力和效率。 这样的技术进步有助于缩小中小企业与大型企业在技术应用上的差距,使更多企业能够享受到人工智能带来的便利。此外,多GPU的支持也意味着更好的扩展性和灵活性,使得这些企业可以根据自身需求调整硬件配置,以适应不同的应用场景。
多机多卡版:由多台装备了芯瞳GPU的计算机构建的高性能集群,能够部署DeepSeekV3及全量R1模型,支持百人以上同时访问,适合大型企业使用。
芯瞳官网上显示,其最新推出的CQ2040 GPU采用了全国产化的生产工艺,基于统一渲染架构设计,集成了1152个流处理器核心,单精度浮点(即FP32)算力达到1.3TFLOPS。该GPU不仅兼容OpenGL、OpenGLES以及Vulkan等多种图形API,还支持WebGL标准。这一产品的推出标志着国产GPU在技术上取得了重要突破,特别是在自主可控方面迈出了坚实的一步。这不仅提升了国内芯片设计的整体水平,也为未来更多应用场景提供了可能。随着技术的不断进步和完善,相信国产GPU将在高性能计算领域发挥越来越重要的作用。
IT新闻最新资讯

2025-08-07 12:23:28

2025-08-07 11:52:33

2025-08-07 11:48:09

2025-08-07 11:29:18

2025-08-07 10:50:12

2025-08-07 10:48:22
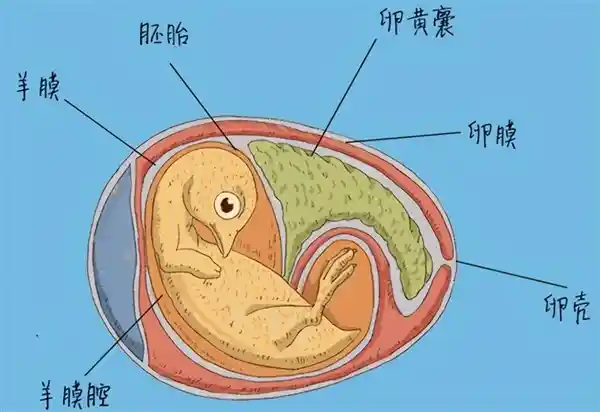
2025-08-07 10:44:06

2025-08-07 10:25:55
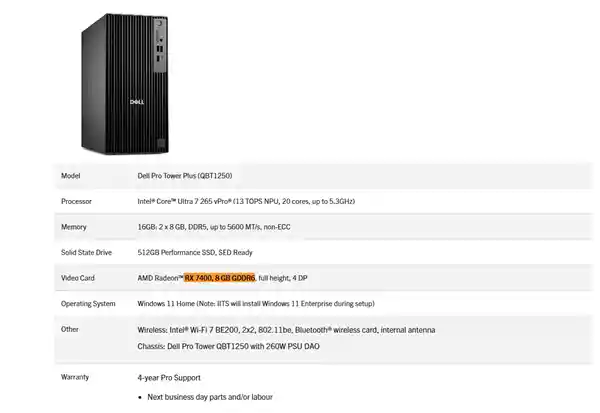
2025-08-07 10:23:09
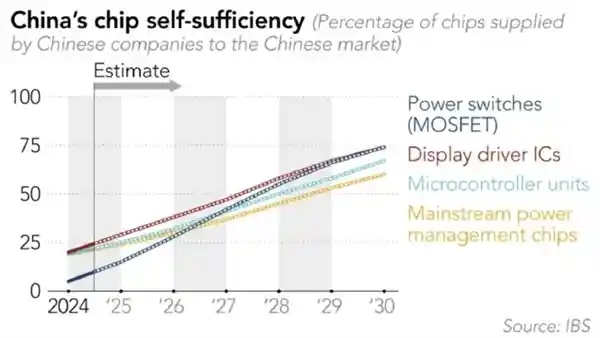
2025-08-07 10:20:44

2025-08-07 10:18:25

2025-08-07 10:16:45

2025-08-07 10:16:18

2025-08-07 10:15:44

2025-08-07 10:13:39
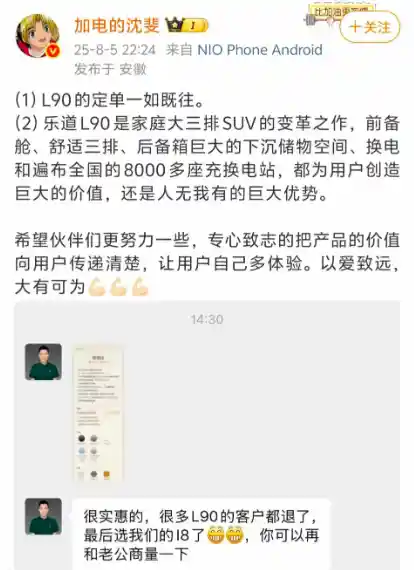
2025-08-07 10:13:24
2025-08-07 10:10:40

2025-08-07 10:10:22

2025-08-07 10:05:35

2025-08-07 10:01:20

2025-08-07 09:58:44

2025-08-04 15:56:43
2025-08-04 15:49:26
2025-08-04 15:36:51
