AI新突破:OpenAI 提出革命性安全对齐方法
AI革命:OpenAI 颠覆传统,引领安全对齐新时代
智慧科技
12月25日,OpenAI的研究团队推出了一种名为“深思熟虑的对齐”(Deliberative Alignment)的新技术,旨在增强AI模型的安全性,并且在o系列模型中已经取得了显著成果。 这一创新技术不仅展示了OpenAI在AI安全领域持续探索的决心,也为我们提供了一个全新的视角来看待如何确保AI系统的可靠性与安全性。通过这种深思熟虑的方法,我们或许能够更有效地解决AI模型可能带来的潜在风险,从而推动人工智能技术更加健康地发展。
如何保证大型语言模型(LLMs)遵循明确的道德和安全规范,目前面临诸多挑战。现有的对齐技术如监督微调(SFT)和从人类反馈中进行的强化学习(RLHF)都有其局限性,存在被操控的风险,可能会生成有害内容、拒绝合理的请求或在不熟悉的场景下表现不佳。
这些问题通常源自现有安全培训的不足,即模型通过数据间接推断规则,而不是明确地进行学习,这通常导致它们缺乏处理复杂场景的能力,从而限制了它们在细微或对抗情境中的有效性。
注:该方法直接教授模型安全规范,并训练它们在生成响应之前推理这些准则进,将安全原则融入推理过程中。
在第一阶段,我们通过监督微调(SFT)技术来训练模型,使其能够理解和遵循一系列的安全规范。这一过程利用了从基础模型生成的数据集进行训练。随后,在第二阶段,我们采用强化学习(RL)策略,并借助奖励模型来评估模型的表现是否符合安全标准。这一阶段的目标是进一步优化模型的推理能力,确保其输出结果更加安全可靠。 这样的训练方法不仅有助于提高模型处理复杂任务的能力,而且还能有效减少潜在的风险。通过分阶段的训练方式,我们可以更系统地提升模型的性能,使其更好地服务于人类社会。这种方法在实际应用中展现出巨大的潜力,有望在未来的发展中为各个领域带来更多的创新与突破。
不同于依靠人工标注数据的方式,“深思熟虑的对齐”采用模型自动生成的数据和思维链(CoT)推理,从而减少了安全训练所需的资源需求。
OpenAI的o1模型已经成功部署,并在抵抗越狱提示方面表现卓越,在StrongREJECT基准测试中获得了0.88的高分,这一成绩远超GPT-4o的0.37分。此外,该技术还显著降低了误拒率,在XSTest数据集中,对于良性提示,o1模型的准确率达到了93%。这不仅表明了o1模型在安全性和准确性方面的显著提升,也标志着人工智能技术在防范滥用和提高用户体验方面迈出了重要的一步。这种进步无疑为未来的AI系统设定了新的标准,同时也提醒我们在追求技术进步的同时,也要不断加强对其潜在风险的管理与控制。
经过深思熟虑的对齐过程,通过训练模型进行明确的安全策略推理,为复杂的伦理难题提供了一个可扩展且易于理解的解决方案。
参考
Deliberative Alignment: Reasoning Enables Safer Language Models
人工智能最新资讯

2025-08-04 15:56:43
2025-08-04 15:49:26
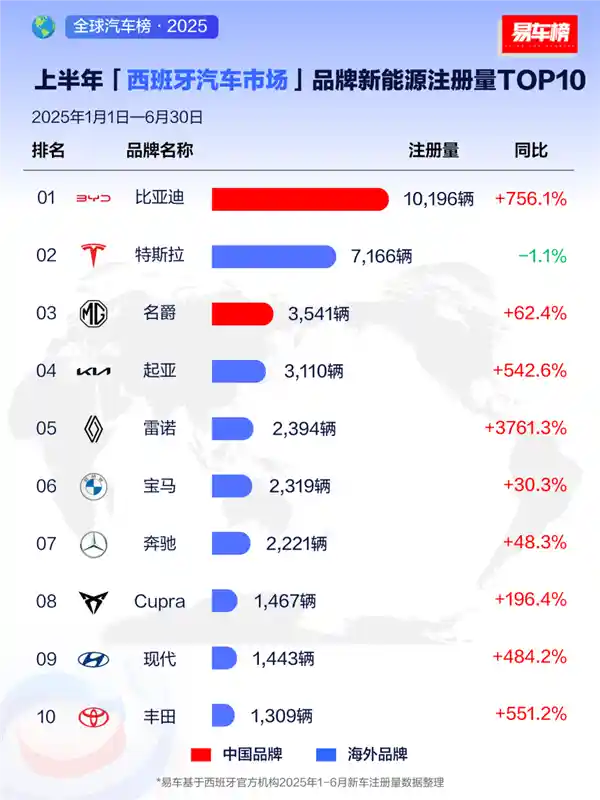
2025-08-04 15:36:51

2025-08-04 15:35:41

2025-08-04 15:34:15
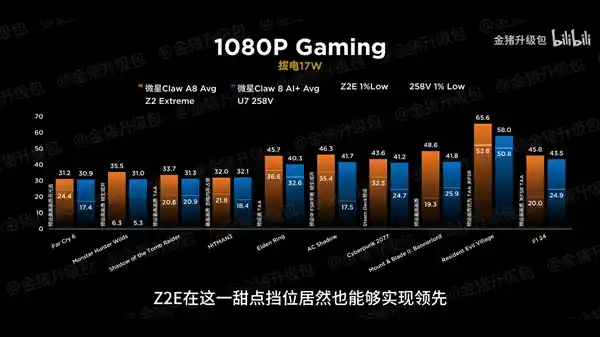
2025-08-04 15:33:03

2025-08-04 15:28:40

2025-08-04 15:25:10

2025-08-04 15:24:56

2025-08-04 15:16:19

2025-08-04 15:12:44
2025-08-04 15:11:41

2025-08-04 15:10:37

2025-08-04 15:10:13

2025-08-04 15:04:23
2025-08-04 15:03:13

2025-08-04 15:02:05

2025-08-04 15:00:04

2025-08-04 14:59:38

2025-08-04 14:57:57

2025-08-04 14:55:16

2025-08-04 14:53:07

2025-08-04 14:50:06

2025-08-04 14:49:51