阿里云发布全球首个多模态推理模型QVQ,开启视觉推理新纪元
多模态推理新时代:QVQ引领人工智能视觉革命
智慧科技
12月25日,阿里云通义千问推出了业界首个开源多模态推理模型QVQ-72B-Preview。该模型在视觉理解和推理方面表现出色,尤其在处理数学、物理和科学等领域中的复杂问题时更为突出。多项评估结果显示,QVQ的表现超越了之前的视觉理解模型“开源王者”Qwen2-VL,其整体性能与“满血版”OpenAI o1、Claude3.5 Sonnet等推理模型相当。目前,开发者可以在魔搭社区和HuggingFace平台上直接体验这一模型。

一个月前,通义团队推出的AI推理模型QwQ-32B-Preview便以卓越的表现获得了SuperCLUE全球开源冠军的荣誉。近期,通义团队在Qwen2-VL-72B开源模型的基础上,进一步开发了多模态推理模型QVQ-72B-Preview。这一新模型不仅能够进行更为细致的逐步推理,其视觉推理能力也得到了显著提升。尤其在处理复杂问题时,QVQ-72B-Preview展现出令人瞩目的表现。这表明,通过结合视觉理解和语言思维,我们正在朝着更加智能的人工智能系统迈进,这无疑为未来的技术发展开辟了新的可能性。 这种结合视觉理解和语言推理能力的进步,不仅提升了人工智能在解决实际问题上的效率和准确性,还预示着人工智能在未来可能达到的新高度。它不仅推动了AI技术的发展,也为跨领域的研究合作提供了更多机会。随着技术的不断进步,我们可以期待看到更多创新的应用场景,这些都将极大地丰富我们的日常生活。

在评估模型视觉理解和推理能力的MMMU评测中,QVQ获得了70.3分,达到了大学水平;在侧重数学视觉推理的MathVista测试中,QVQ的表现超过了OpenAIo1,证明了其卓越的图形推理能力;在更为全面和多学科的MathVision评测中,QVQ的表现优于Claude3.5和GPT4o,表明QVQ在解决实际数学问题方面更为出色;在奥林匹克级别的OlympiadBench基准测试中,QVQ同样展示了其优秀的视觉推理能力。
QVQ是一款能够进行深度视觉推理的大模型。它不仅具备更精准的视觉感知能力,还能进行细致入微的分析与推理。QVQ具有质疑自身假设的能力,会仔细检查其推理过程中的每一个步骤,最终通过深思熟虑得出结论。它可以轻松解读“梗图”的含义;观察真实照片时,能够合理推测出物体的数量和高度等信息。在处理数学、物理、化学等各学科难题时,QVQ能够像人类甚至科学家一样,展示其思考过程并提供准确的答案。
目前,QVQ-72B-Preview已在魔搭社区和HuggingFace等平台上开源,开发者可以轻松体验。据悉,一个月前发布的推理模型QwQ受到了全球开发者的热烈欢迎,一经推出便登上了HuggingFace模型趋势榜首位。截至Qwen的衍生模型数量已超过7.8万个,成功超越Llama,成为全球规模最大的AI模型群。
人工智能最新资讯

2025-08-04 15:56:43
2025-08-04 15:49:26
2025-08-04 15:36:51

2025-08-04 15:35:41

2025-08-04 15:34:15
2025-08-04 15:33:03

2025-08-04 15:28:40

2025-08-04 15:25:10

2025-08-04 15:24:56

2025-08-04 15:16:19

2025-08-04 15:12:44
2025-08-04 15:11:41

2025-08-04 15:10:37

2025-08-04 15:10:13

2025-08-04 15:04:23
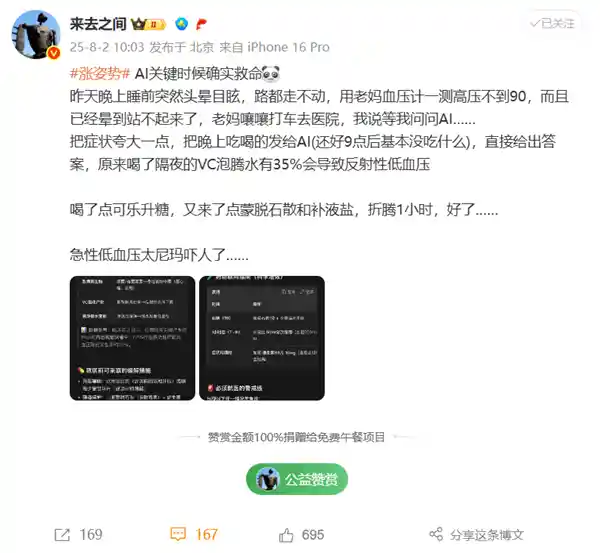
2025-08-04 15:03:13

2025-08-04 15:02:05

2025-08-04 15:00:04

2025-08-04 14:59:38

2025-08-04 14:57:57

2025-08-04 14:55:16

2025-08-04 14:53:07

2025-08-04 14:50:06

2025-08-04 14:49:51