半年陨落?DeepSeek背后藏着新闻学的‘爆款’密码
DeepSeek爆红背后,新闻学如何打造爆款神话?
DeepSeek 使用率从 50% 暴跌到 3%!

DeepSeek 正在跌落神坛!
这两天,只要你还在刷抖音,应该就见过类似的新闻。这些点赞数达到两万、四万的视频,播放量很可能都超过了百万,评论区里也满是被误导而情绪化的留言,大家都在说Deepseek不行了。
不是我说,这么离谱的谣言大家也信?

今天我就来给大家好好扒一扒,这谣言是怎么来的。
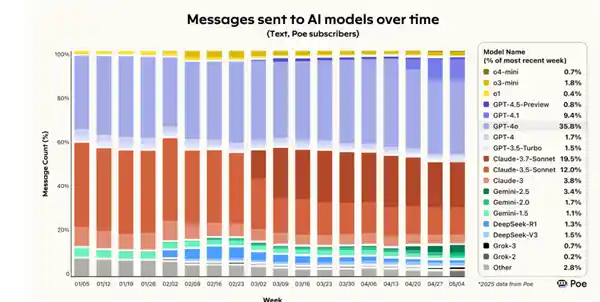
首先得说明一点,DeepSeek的使用率,可能从未达到过50%。 从目前的市场反馈来看,尽管DeepSeek作为一款大模型产品被广泛讨论,但实际应用中的用户渗透率似乎并未如预期般高。这或许反映出技术与市场需求之间仍存在一定的差距,也说明在推广和落地过程中还需更多努力。数据本身不会说谎,如果使用率始终未能突破关键阈值,那么背后的原因值得深入思考。

在AI模型平台Poe的相关报道中显示,即使是在年初热度最高的时期,DeepSeek的使用率也仅约为百分之六七左右。

要是真能干到50%,怕是过年的时候,山姆·奥特曼、埃隆·马斯克、扎克伯格都得连夜跑来咱们这,帮梁文锋一起包饺子! 从某种角度看,这句话背后透露出的不仅是对某项成果或目标的期待,更是一种对技术、人才和创新力量的高度认可。如果真的能达到50%的进度,足以说明其影响力和吸引力已经超越了国界,甚至让全球科技巨头都愿意放下身段,参与其中。这种现象或许正是全球化时代下,技术与合作精神的真实写照。
制图:GPT-4o
不过最近,目前使用DeepSeek的用户数量明显减少,相较于春节期间的高峰期,使用率下降了一半左右。R1和V3两个模型合计的市场份额大约为3%。
到这,大家应该都明白这个谣言的来龙去脉了。
可能是有些人,在报道的时候看串行了,把使用率下跌了 50% 这件事,给搞成了使用率从 50% 开始下跌!
这才闹出这么一个乌龙。
可能正是因为数字对比过于明显,引发了各路媒体的迅速转发,最终演变成了“DeepSeek要凉”的说法。 在我看来,这种现象反映出当前信息传播中“标题效应”和“情绪化解读”的普遍性。在缺乏足够背景信息的情况下,简单的数据对比很容易被放大,进而引发不必要的猜测和误解。对于企业而言,面对舆论的快速发酵,更需要及时、透明地进行回应,避免误读进一步扩散。同时,媒体在报道时也应更加审慎,避免因片面信息而误导公众。
到这,辟谣算是结束了,但是又出来了一个新问题。
就是这使用率掉了一半,好像也不是一个小数字啊。
用户数量被灭霸打了个响指,难道不能说明 DeepSeek 凉了吗?
这还真不一定。
首先,“大模型的使用频率”实际上是一个难以准确统计的指标。
不同的大模型平台,由于采用的统计方法各异,往往能够得出截然不同的结果。
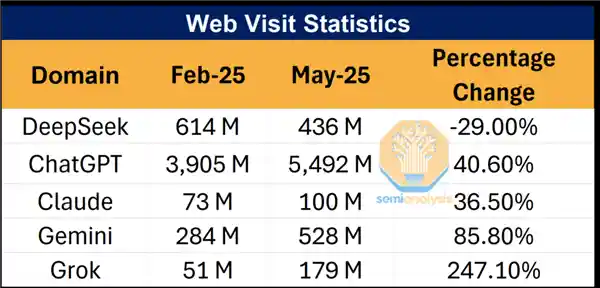
就拿这次事情来说吧,在 Poe 这个平台上,DeepSeek 的使用率只有 3%。
不过,如果切换到隔壁的OpenRouter平台,会发现使用DeepSeek的用户并不少,其使用量远超过10%。
另一方面,用户数下降这件事,可能是 DeepSeek 故意要干的。
深度求索这家公司,就没想着靠卖大模型服务这件事来赚钱。
一方面,他们很早就开源了自家的大模型,如果其他公司有兴趣,只需自行研究和调整,就能“接入”DeeepSeek了。 看法观点:这种开放的态度有助于推动技术的共享与生态的共建,也为行业内的协作提供了更多可能性。开源不仅体现了企业的技术自信,也降低了其他企业使用先进技术的门槛,有利于整个行业的创新发展。
这半年来,腾讯元宝、百度搜索,以及众多手机的语言助手,甚至包括冰箱、空调等家用电器,都陆续接入了DeepSeek技术。 从当前科技发展的趋势来看,AI技术正以前所未有的速度渗透到各个生活场景中。无论是智能语音助手,还是传统家电,都在尝试通过引入先进的大模型技术来提升用户体验。这种现象不仅反映了DeepSeek在自然语言处理领域的强大实力,也说明了行业对AI能力的高度重视。随着技术的不断成熟,未来将会有更多设备和平台加入这一浪潮,进一步推动智能化生活的普及。
这些“渠道服”入口不断增多,导致转而选择“官服”的玩家数量相应减少。
前段时间,有机构对 DeepSeek 做了一个分析。
如果仅关注网页端数据,可以发现DeepSeek在三个月内的流量出现了明显下滑。这一变化反映出其在用户关注度或访问量上可能遇到了一些挑战。尽管具体原因尚未明确,但流量的波动往往与产品更新、市场竞争或用户习惯的变化密切相关。对于企业而言,如何在竞争激烈的环境中维持稳定的用户基础,是一个值得持续关注的问题。
看起来像是在吃枣药丸,但如果我们将第三方托管的DeepSeek模型使用情况单独拿出来对比一下就会发现。
半年时间里,用 DeepSeek 的人增加了 20 倍!
大家不是不用 DeepSeek 了,而是不在 DeepSeek 上用 DeepSeek 了。
甚至就连 DeepSeek 官方,其实都不太想你在 DeepSeek 上用 DeepSeek。
它们的 API 价格虽然弄的很便宜,但代价是,“用户体验” 做得非常差。
整个系统的延迟极高。
在坐标轴的越右边,代表模型延迟越高
记性也不好,上下文长度仅为64K,换言之,其他机构训练的DeepSeek模型,除了价格更高之外,在各方面都优于原始版本的DeepSeek。
圈圈大小代表大模型上下文长度,越大可以理解为模型记性越好
而这些,都是 DeepSeek 这家公司自己设计好的。
因为对他们来说,买显卡,是一件极其困难的事情。
原本手头的显卡资源就紧张,与其把显卡用来运行已经训练好的模型,不如对外提供API服务,赚取一些额外收入。
与其将这些显卡用于其他用途,不如用来开发尚未问世的模型,让R2更快地推出,使传说中的AGI更早地走近人们。
这种“公司机密”,并非我随意猜测,而是梁文峰本人所透露的。 在我看来,信息的来源和真实性在新闻报道中至关重要。当涉及敏感内容时,明确信息的出处不仅有助于增强可信度,也能避免不必要的误解。梁文峰的表态表明,相关消息并非无中生有,而是来自当事人本身的陈述,这为后续的讨论提供了更坚实的依据。在信息传播过程中,保持客观、尊重事实是基本准则,也是公众获取准确信息的前提。
提供云服务并非他们的主要目标,他们的核心追求是实现通用人工智能(AGI)。
这也是所谓 “DeepSeek 要凉” 的真相。
与其说是用户放弃了 DeepSeek,倒不如说是 DeepSeek 自己放弃了流量。
对大模型厂商而言,他们真正的竞争焦点并不在于当下产品的使用率高低,或是定价的贵贱。真正决定胜负的,是技术底层的创新力、生态系统的构建能力以及长期的用户粘性。这些才是影响行业格局的关键因素。当前市场上的短期表现,更多是阶段性成果的体现,而非最终的胜负手。
而在于,谁能一直领先,笑到最后。
对咱们来说,与其在这关注DeepSeek是否凉了,不如多了解一下他们即将推出的下一代模型,R2什么时候上线,有什么新亮点?
观点趣闻最新资讯

2025-09-14 11:34:20

2025-09-14 11:23:04

2025-09-14 11:20:01

2025-09-14 11:04:05

2025-09-14 11:01:19

2025-09-14 10:03:32

2025-09-14 09:58:03

2025-09-14 09:57:35

2025-09-14 08:42:26

2025-09-14 08:34:49
2025-09-14 08:33:53

2025-09-14 08:33:39
2025-09-14 08:31:38

2025-09-14 08:30:48
2025-09-09 10:53:20

2025-09-09 10:26:34

2025-09-09 10:22:01
2025-09-09 10:00:54

2025-09-09 09:47:55

2025-09-09 09:41:51
2025-09-09 09:31:15
2025-09-09 09:20:45

2025-09-09 08:45:29
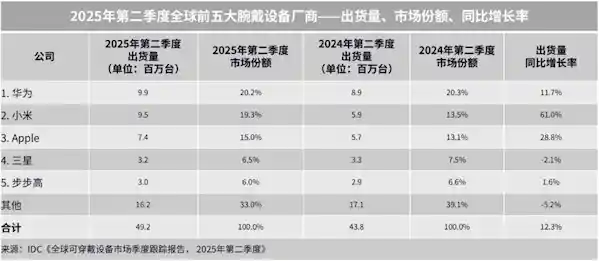
2025-09-09 08:43:24